Ensuring the lawfulness of the data processing - In case of re-use of data, carrying out the necessary additional tests and verifications
If it re-uses data previously collected, the data controller is required to carry out certain additional verifications to ensure that that the processing is lawful. The CNIL helps you determine your obligations, depending on the means of collecting the data and its source.
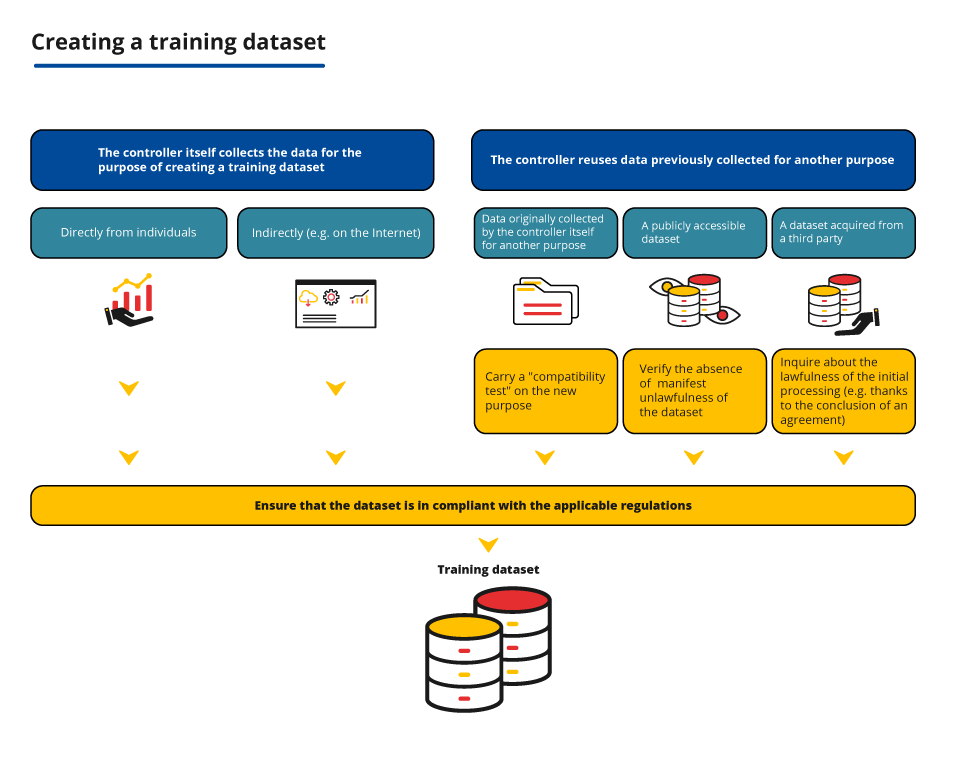
The principle
In some cases, depending on the methods of collection and the source of the data used for the creation of the training dataset, the controller is required to carry out certain verifications to ensure that the processing of data is lawful. These verifications must be carried out in addition to the identification of the legal basis for the processing.
In practice
The provider reuses the data it originally collected for another purpose
A data controller may wish to reuse the data it has collected for an initial purpose (e.g. in the context of providing a service to individuals) in order to create a training dataset.
In that case, it must determine whether that further processing is compatible with the purpose for which the data were originally collected, where the processing is not based on the data subject’s consent or on Union or Member State law.
The obligation to carry out this “compatibility test” applies to the further processing of data (within the meaning of Article 6.4 GDPR), i.e.:
- which have not been foreseen or brought to the attention of data subjects when collecting the data;
- which are carried out by the same controller who decides to re-use data for a purpose distinct from the purpose for which it was collected, including when it comes to publishing it on the Internet or sharing it with third parties for re-use for another purpose.
Please note: no compatibility test is required for the intended purposes and brought to the attention of the data subjects as soon as they are collected in accordance with the principle of transparency, including where some of them may appear secondary or accessory. For example, the sharing of data by a controller with its processor for the improvement of the performance of its algorithm does not require a compatibility test, if this purpose was intended and brought to the attention of the data subject (subject to its compliance with the conditions of legality for this purpose of improving the algorithm).
In order to carry out this “compatibility test”, it must take into account in particular:
- the existence of a link between the initial purpose and the purpose of the intended further processing;
- the context in which the personal data was collected, in particular the reasonable expectations of the data subjects, depending on the relationship between the data subjects and the controller;
- the type and nature of the data, in particular according to its sensitivity (biometric data, geolocation data, concerning minors, etc.);
- the possible consequences of the envisaged further processing for the data subjects;
- the existence of appropriate safeguards (such as encryption or pseudonymisation).
Where the reuse of the data pursues statistical or scientific research purposes, the processing is presumed to be compatible with the original purpose if it complies with the GDPR and if it is not used to make decisions regarding the data subjects. The compatibility test is therefore not necessary.
In order to pursue a statistical purpose within the meaning of the GDPR, the processing must only aim at the production of aggregated data for themselves: the sole purpose of the processing must be the calculation of the data, their display or publication, their possible sharing or communication (and not taking subsequent decisions, individual or collective). The statistical results thus obtained must constitute aggregated and anonymous data within the meaning of the data protection regulations. The use of statistical techniques of machine learning is not enough to consider that they are processing “for statistical purposes”, since the purpose of processing is not to produce aggregated data for themselves. The use of these techniques is more of a mean to train the model.
The notion of “scientific research” is broadly understood in the GDPR. In summary, the aim of the research is to produce new knowledge in all areas in which the scientific method is applicable. Any processing of data for scientific research purposes must be subject to appropriate safeguards for the rights and freedoms of the data subject, such as anonymisation or pseudonymisation (referred to in Article 89 GDPR).
- Scientific research (excluding health) [In French]
Please note: even when the further processing is compatible, a valid legal basis must always be identified and the data subjects informed, in particular in order to be able to exercise their rights.
Focus: under what conditions can a dataset originally constituted for scientific research purposes be reused?
The GDPR facilitates the reuse of data for scientific research purposes: this reuse is considered compatible with the original purpose of the processing and certain derogations (in particular to the rights of individuals) are possible.
On the other hand, where a controller has processed data for scientific research purposes and intends to reuse them for other purposes (on its own behalf or to transmit it to a third party), it must comply with certain conditions.
- The reuse of a dataset will be possible:
- if the data have been previously anonymised, or
- if the reuse is compatible with the purpose for which the controller collected the data (according to the “compatibility test” detailed above) and the new processing is implemented in compliance with the GDPR (information to individuals about this new purpose, identification of a legal basis, etc.). The derogations allowed by the GDPR for scientific research will no longer be mobilised.
In the event of transmission of the data to third parties, the compatibility of further reuse with the research purpose may be guaranteed in particular by a license.
The provider reuses a publicly accessible dataset
Datasets containing personal data may be freely made available on the Internet outside the legal framework for open data. Most often, it corresponds to data that were already publicly accessible and that constitute a dataset or corpus disseminated on the website of a university or a platform dedicated to sharing datasets, to facilitate their re-use.
Checking the lawfulness of making the dataset available online is primarily the responsibility of the controller who put the dataset online (where appropriate, by ensuring that it is a compatible further processing if it had not initially collected the data for that purpose). However, in order to be able to rely on a valid legal basis under the GDPR, the controller who reuses the data must ensure that they are not reusing a dataset whose creation was manifestly unlawful (e.g. from a data leak).
The re-user may not re-use an established or uploaded dataset for which they cannot ignore that they do not comply with the GDPR (Article 5.1.a GDPR) or other rules, such as those prohibiting breaches of the security of information systems or infringements of intellectual property rights.
In addition, the person who downloads or reuses a manifestly illegal dataset may be guilty of the offence of concealment (Article 321-1 of the French Criminal Code).
The possibility of reusing freely a dataset made available on the Internet is not necessarily subject to in-depth verifications on compliance with all GDPR rules or other applicable legal rules (copyright, data covered by business secrecy, etc.), which are primarily under the responsibility of the organisation that uploads the data. However, an organisation cannot reuse a dataset that would be manifestly unlawful.
This obvious illegality must be assessed on a case-by-case basis. As such, the CNIL recommends that re-users ensure that:
- The description of the dataset mentions their source.
- The creation or dissemination of the dataset is not manifestly the result of a crime or an offence nor has been the subject of a public conviction or sanction by a competent authority which involved the deletion or prohibition of further use of the data;
- there is no clear doubt that the dataset is lawful (in particular that the initial processing is not manifestly lacking a legal basis when the data are so intrusive that they cannot be processed without the consent of the individuals), ensuring in particular that the conditions for collecting the data are documented enough;
Conversely, it would be possible to create a dataset from another dataset whose description leaves no clear doubt as to its lawfulness. For example, a pseudonymised dataset, initially made public by data subjects on an identified website and that does not contain sensitive data.
The same applies to the reuse of an aggregated dataset that the diffuser would present as anonymous. For example, an organisation that wishes to create a training dataset to develop an AI system able to predict the socio-economic impact of population ageing could reuse anonymous aggregated datasets containing demographic information (number of active persons, age of persons, fertility rate or elderly dependency rate).
- the dataset does not contain sensitive data (e.g. health data or political opinions) or infringement data (as defined in Articles 9 and 10 GDPR) or, if it contains such data, it is recommended to carry out additional verifications to ensure that such processing is lawful (mainly for sensitive data to ensure explicit consent of data subjects, or that the data have been clearly made public by the data subjects as specified below and for data relating to infringements that such use is made possible by the French Data Protection Act).
Such prior verifications could be included in the Data Protection Impact Assessment (DPIA).
Certain failures committed by the controller to create and disseminate a dataset do not systematically and irreparably impact the lawfulness of the processing carried out by the re-user. Thus, a re-user may use a dataset with minor illegalities, provided that the reuse meets the requirements of the GDPR.
The provider reuses a dataset acquired from a third party (data brokers, etc.)
Some providers wish to create a training dataset from datasets owned by third parties.
For the third party who shares personal data, this means ensuring the lawfulness of this transmission
- Case 1: the data was collected specifically to be shared to create a training dataset
The third party will have to ensure that the processing of data transmission complies with the GDPR (definition of an explicit and legitimate purpose, identification of a valid legal basis, information to data subjects and management of the exercise of their rights, etc.) for which they assume responsibility.
- Case 2: the third party did not initially collect the data for this purpose
Where the third party initially collected the data for other purposes (e.g. in the context of the provision of a service to data subjects), it is for the third party to ensure that the transmission of such data is for a purpose compatible with the purpose(s) which justified its collection. It will therefore have to carry out a “compatibility test”.
Note that the initial owner of a dataset sometimes authorises its use under a license agreement that provides for its terms and conditions (in particular under intellectual property law). This license agreement can, for example, regulate this compatibility by limiting possible reuse.
For the re-user, this usually involves a series of verifications of the initial controller’s processing
The controller must ensure that they do not re-use a dataset whose creation or transmission was manifestly unlawful (for example, in the absence of an indication as to its source, in case of blatant doubt as to its lawfulness, in particular in the case of the processing of sensitive data, etc.). This results from the general principle of lawfulness of processing in Article 5.1(a) GDPR, in addition to the risk of being guilty of the offence of concealment (Article 321-1 of the French Criminal Code). This implies for the controller to carry out at least the same verifications as those set out in the section above.
The re-user of a dataset transmitted by a third party will be all the less likely to ignore that the dataset was created or shared in breach of the GDPR or of more general rules (such as those prohibiting breaches of the security of information systems or infringements of intellectual property rights) since its relationship with that third party allows it to remove any doubts that it may have.
An agreement between the initial data holder and the re-user is thus recommended in order to enable the latter to ensure the lawfulness of its own processing, even if it is not explicitly required by the GDPR.
In this regard, the CNIL recommends providing a number of indications in the contract such as:
- the source, the context of the data collection, the legal basis for the processing and the data protection impact assessment (see in particular how-to sheet 5 on the implementation of a DPIA) if necessary, in order to avoid the risks of having an unlawful dataset;
- the information provided to the data subjects (especially with regards to the purpose and the recipients);
- any guarantees as to the lawfulness of this data sharing by the original data holder (e.g.: the compatibility of the purpose, the lawfulness of sharing, etc.).
The CNIL provides a description sheet of the dataset that can be used for this purpose.
Please note: if the re-user wishes to base his processing on consent obtained by a third party, they must be able to prove that valid consent has indeed been obtained from the data subjects. The obligation to provide proof of consent cannot be fulfilled by the mere presence of a contractual clause requiring one of the parties to obtain valid consent on behalf of the other party. Such a clause does not allow the organisation to guarantee, in all circumstances, the existence of valid consent (see the CNIL's deliberation no. SAN-2023-009 of 15 June 2023). The contract may, on the other hand, be used to frame:
- the mechanisms put in place to demonstrate the collection of valid consent;
- the provision of evidence to the organisation wishing to rely on the consent of data subjects;
- where applicable, the conditions under which such evidence must be retained, in particular in order to maintain its probative value.
In addition to these prior verifications, and regardless of the method of collection used, re-users must ensure that their own processing are fully compliant.
It should be noted that this obligation also applies when they reuse datasets whose creation and dissemination do not fall within the scope of French or European law. For more information on the territorial scope of the GDPR, see the how-to sheet “What is the scope of the AI how-to sheets”.
In particular, the re-user must ensure compliance with the requirements regarding the persons whose data is present in the dataset thus obtained. They must inform them of the processing that they wish to implement, and allow them to exercise their rights.

